민초로그
tanstack-query 도입 후 쌓인 기술부채 갚기
Development
2025-10-12
17 Min Read
이 글에서는 tanstack-query를 설명하기 위한 내용보다는 도입 후 사용하면서 겪은 문제를 팀과 이야기하며 해결했던 내용과 그에 대한 제 생각을 적어봤어요.
초기 팀에 합류하여 프로젝트를 구성하면서 Pinia라는 전역 상태관리 라이브러리에서 외부 상태를 주입해서 의존성을 가지는 복잡한 구조에서, Pinia는 클라이언트 상태 관리로 두고 tanstack-query를 서버 상태 관리로 관심사를 명확하게 분리해냈어요.
또한 data fetching로직에 일관성을 재정립하고 불필요한 로직을 제거해냈어요. 그렇게 어느 정도 수준의 컨벤션을 팀원들과 논의했어요.
도입이 1년 가까이 됬을 무렵 적용된 코드의 사소한 곳에서 문제가 쌓여나갔고 이를 팀원들과 함께 얘기하며 정리했어요.
queryKey 관리 방식의 부재
서버 데이터를 fetching한 후 이 쿼리(받아온 서버데이터를 쿼리로 정의할게요.)는 개발자가 부여한 queryKey값을 기반으로 캐싱돼요. 그런데 서비스가 커지면 그 만큼 관리해야할 query가 많아지게 되죠. 그래서 전략적으로 queryKey를 관리해야할 필요가 있었어요.
tanstack-query의 메인테이너인 Tkdodo는 다음과 같은 queryKey factory방식을 추천하고 있어요.
// query-key-factory
const todoKeys = {
all: ['todos'] as const,
lists: () => [...todoKeys.all, 'list'] as const,
list: (filters: string) => [...todoKeys.lists(), { filters }] as const,
details: () => [...todoKeys.all, 'detail'] as const,
detail: (id: number) => [...todoKeys.details(), id] as const,
};말그대로 특정 도메인마다 factory형식으로 관리하는 방식이에요. 동적으로 queryKey를 관리하다보니 휴먼 에러 방지에도 적합한 방법으로 생각했어요. 유사한 방식으로 Query Key Factory라는 라이브러리도 있었지만, 굳이 외부 라이브러리 의존성까지 생각하며 관리 이점을 챙겨가고 싶지는 않았어요. 그래서 팀원들의 미팅이 있기전까지는 첫번째 방식인 도메인마다 queryKey factory를 구성하여 관리하기를 생각했어요.
하지만 팀원의 의견을 조금은 달랐어요. 프로젝트 기능 개발에 시간적 여유 부족과 관리를 위한 관리를 하게 된다는 생각이 팀원들에게는 부정적으로 다가왔어요. 그래도 프로젝트의 볼륨이 커질수록 관리가 힘들어지기 때문에 다음과 같은 내용으로 컨벤션을 합의했어요.
자주 사용하는 key는 상수로 관리해요.
특정 도메인이나 정적으로 많이 사용되는 문자열 등을 상수로 한 곳에서 일괄적으로 관리하여 오타와 같은 휴먼 에러를 방지하기로 했어요.
//예시
const QueryKey = {
TODO : 'todo',
USER : 'user',
ALL : 'all',
FILTER : 'filter',
DETAIL : 'detail',
INFINITE : 'infinite'
} as const;
// example
-> [QueryKey.USER, QUERYKEY.ALL]팀의 상황에 따라 이 정도에서 마무리 했지만, 여유 상황이 생기면 factory를 기반으로 다시 queryKey를 설계하자는 의견을 공유할 예정이에요. 이후에 서비스 규모가 커질수록 관리해야하는 캐싱 데이터도 많아져서 쿼리가 중복, 제거, 초기화할 때 문제가 생기기 쉽고 디버깅하기도 어렵기 때문이에요.
데이터를 식별하기 위한 id는 해당 도메인 네이밍과 결합하여 사용해요.
다른 구분해야 할 도메인이나 여러가지 옵션이 붙은 경우에는 단순히 id나 key와 같은 식별자는 명확히 알아보기가 힘들어요. 그래서 관련 도메인 prefix로 붙여서 구분하고 있어요.
// ❌
[QueryKey.USER, id]
// ✅
[QueryKey.USER, userId]
// example
-> [QueryKey.USER, userId, QueryKey.TODO, todoId]이렇게 하면 도메인 간의 구분이 명확해지고 쿼리키를 파악하기 쉬워요.
옵션과 같은 문자열이나 상수를 포함시키면 객체로 표현해요.
// ❌
[QueryKey.USER, page, size, filter]
// ✅
[QueryKey.USER, { page, size }, { filter }]
// example
-> [QueryKey.USER, userId, QUERYKEY.TODO, { page, size }, { filter }]특정 값에 대한 정보를 잘 파악할 수 있도록 객체로 만들어야 해요(유사한 옵션은 동일한 객체로 묶어요). 그리고 단순히 특정 상세 데이터를 얻기 위한 userId나 todoId는 도메인 queryKey다음에 위치시키고 객체로 표현하지 않아요.
이렇게 객체화하여 작성하는 이유는 tanstack-devtools에서 명확하게 쿼리를 파악하기 위해서예요.
AS-IS
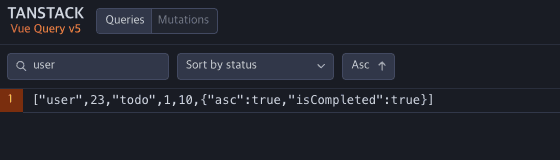
TO-BE
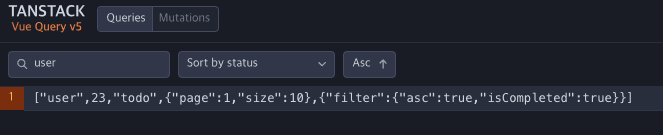
devtool에서 확인한 객체화된 키값들로 쿼리를 명확하게 파악할 수 있어요.
⚙️ queryKey 내부 해쉬화 과정
앞서 살펴본 queryKey를 개체화 하는 과정에서 한 가지 의문이 들 수 있어요.
"queryKey 요소를 객체로 표현하면 불변성을 지키지 못해 쿼리키 내부에서 새로 갱신하지 않나요?"
좋은 접근이에요! tanstack에서는 내부적으로 query-key를 효율적으로 관리하고 있어서 문제가 없어요.
queryKey : [ 'users', { page, filter }]
queryKey : [ 'users', { filter, page }]객체 내부에서 정보를 순서를 바꾸더라도 변수값이 변경되지 않으면 동일한 값으로 인식해요. deterministic way(입력과 조건이 동일할 때, 일관되게 동일한 결과를 가져오는 방식)로 해시화되기 때문이에요.
query-core util패키지에서 이를 확인할 수 있어요.
/**
* Default query & mutation keys hash function.
* Hashes the value into a stable hash.
*/
export function hashKey(queryKey: QueryKey | MutationKey): string {
return JSON.stringify(queryKey, (_, val) =>
isPlainObject(val)
? Object.keys(val)
.sort()
.reduce((result, key) => {
result[key] = val[key]
return result
}, {} as any)
: val,
)
}queryKey를 json으로 직렬화를 하며 내부 객체는 객체의 key를 바탕으로 sorting처리하고 있어요.
const queryKey1 = [QueryKey.USER, { page:0, size:20 }]
const queryKey2 = [QueryKey.USER, { size:20, page:0 }]
hashKey(queryKey1) === hashKey(queryKey2)
'["USER",{"page":0,"size":20}]' === '["USER",{"page":0,"size":20}]'즉, 객체 내부에서 순서가 바뀌어도 동일한 값으로 해시화되어 동일한 쿼리로 인식해요.
selecter 패턴 사용에 지양하기
useQuery에는 옵션으로 selecter패턴을 구성할 수 있어요. 여기서 selecter패턴을 사용하면 원하는 구조를 구성하고 원하는 데이터 본질에만 집중할 수 있어요. 또한 사용하는 쪽에서 구조적으로 공유가 되어, 내부적으로 캐싱되어 리렌더링을 방지하는 등의 최적화도 이루어져요.
그래서 초기에는 팀에서 selecter패턴을 이용해 원하는 포맷으로 query를 추출하는 모습을 쉽게 찾아 볼 수 있었어요.
// example
type DeviceInfo = {
modelName: string;
modelNumber: number;
modelId: string;
manufacturingYear: string;
manager: string;
power: boolean;
///...기타 등등
};
const useGetDeviceInfo = (id: number) => {
return useQuery({
queryKey: [QueryKey.DEVICE, id],
queryFn: () => deviceApi.getDevice(id),
select: (record) => {
return [
{
label: "모델명",
value: record.modelName,
},
{
label: "모델번호",
value: record.modelNumber,
},
{
label: "제작년도",
value: record.manufacturingYear,
},
];
},
});
};하지만 이렇게 selecter패턴을 사용하게 되며 백엔드에서 받은 데이터의 유연성과 재사용성이 떨어져요. 예를 들어 A라는 페이지는 모델명,모델번호,제작년도와 같은 속성이 필요해도 B페이지는 Device API로 받아온 모든 속성이 필요할지도 몰라요.
또 하나의 문제는 dev-tool에서 해당 쿼리키에 매칭되는 data가 select로 포맷팅한 형식이 아닌 원본 데이터로 노출되요. 저희는 이 구조가 일관성이 없다고 판단했어요.
devtool에서 확인한 원본 데이터로 select로 변형된 값은 찾아볼 수 없어요.
이러한 이유들로 인해 selecter패턴으로 얻는 장점보다는 디버깅과 직관성을 위해 selecter패턴 사용을 지양하고 있어요.
일관성 있는 인터페이스 반환 값
뷰 로직과 외부 api 연동사이에 중간 Layer훅을 두었을 때, 이 훅이 반환하는 값의 일관성에 대해 이야기가 나왔어요. 반환 방식이 개발자마다 다르기 때문에 일관성이 떨어져 예측가능성이 떨어진다는 이야기에요.
const useUser = () => {
const { data, isLoading, refetch } = useQuery(userQueryOptions)
watch(() => data.isAdmin, () => {
notificate(data.isAdmin)
// 로직 생략.....
})
return { data, isLoading, refetch}
}
// 사용하는 쪽에서 예측이 블가능...
// ❌
const { isFetching } = useUser()마침 토스 frontend fundamental에서도 저희 상황과 똑같은 이야기를 하고 있었어요.
// ✅
const useUser = () => {
const userQuery = useQuery(userQueryOptions)
watch(() => data.isAdmin, () => {
notificate(data.isAdmin)
// 로직 생략.....
})
return userQuery
}결국 이러한 같은 종류의 훅에 대해서 항상 query값을 반환처리 하기로 했어요.
tanstack-query 도입 후 팀원이 겪은 어려움 분석
저는 이제까지 tanstack-query를 사용해와서 익숙했어요. 하지만 초기에 처음 사용해보거나 익숙하지 않은 팀원들은 어려움을 겪었어요. 새로운 기술을 학습하거나 적용할 때는 낯섦이라는 진입장벽이 존재해요. 그래서 주된 진입장벽이 무엇인가에 대해 추측해봤어요.
// React
const User = (userId: string) => {
const { data, isLoading, refetch } = useQuery({
queryKey: [QueryKey.USER, userId],
queryFn: () => userApi.getUser(userId),
})
////..생략
return <UserComponent userData={data} />
}일반적으로 tanstack-query를 사용에 익숙하지 않은 사람도 위의 코드를 보면
queryKey를 기반으로 캐싱하고 queryFn에 promise기반의 비동기 함수를 통해, 트리거 되면 해당 query를 얻을 수 있다고 어느정도 추론할 수 있어요.
그런데 문제는 그 실제 동작에서의 추론 과정이에요.
useQuery를 선언함으로써 쿼리를 서버로부터 받아오고 캐싱하는 건 알겠는데, 어느 시점에 트리거 되는거지?? 컴포넌트가 마운트될때?? 따로 트리거 해주는 것은 없는건가?? 다시 실행시키면 어떤 값을 의존하는거지??
일반적으로 서버 데이터를 fetching할 때 어떤 행위를 하고 어떤 결과를 일으키는지(명령형)를 개발자가 직접 작성해야 해요. 이러한 행위를 코드로 작성하고 개발자가 원하는 시점에 실행하는 것이 일반적인 방식이예요.
// React Example
const fetchData = async (userId: string) => {
const response = await fetch(`/api/users/${userId}`);
const data = await response.json();
return data;
}
const User = (userId: string) => {
const [userData, setUserData] = useState()
// 어느 시점에 data fetch로직이 트리거 되는지 알 수 있음.
useEffect(() => {
const fetchUserData = async() =>{
const userdata = await fetchData(userId);
setUserData(userdata);
};
fetchUserData();
}, []);
return <UserComponent userData={userData} />
}그 전에는 위와 같은 방식으로 data fetching로직에 대해 명령형 방식으로 작성했었어요.
또한 userId와 같이 동적으로 변경되는 쿼리키의 값을 기반으로 다시 fetching동작을 트리거하지만, refetch라는 동작이 어느 시점의 쿼리키를 기반으로 동작하는지 혼동하는 경우가 발생했어요.
이러한 방식이 tanstack-query의 선언형 방식과 마찰이 존재하여 혼란을 야기시켰던 것 같아요. 암시적으로 처리되는 부분이 추상화되어 있기때문에 코드의 흐름이 직관적이지 않아 팀원들이 적응 초반에 어려움을 겪었던 것 같아요.
마무리

다른 모든 기술과 마찬가지로 tanstack-query가 가져오는 분명한 트레이드오프가 있었어요. 선언형 데이터 흐름과 강력한 캐싱은 개발자 경험과 운영 안정성을 크게 끌어올렸어요. 반면 초기 학습 곡선, 암묵적 트리거에 대한 직관성 저하, queryKey관리 비용 같은 단점도 있었어요.
문제를 줄이기 위해 자주 쓰는 queryKey를 상수로 모으고, 식별자는 도메인 친화적으로 이름 붙이며, 옵션은 객체로 명시해 devtools에서 추적 가능성을 높이는 여정이 있었어요. 또한 selecter 패턴을 지양하고 훅은 쿼리 객체 자체를 일관되게 반환해, 재사용성과 예측 가능성을 확보했어요.
트레이드오프는 무조건 뒤 따라오며, 이를 극복하기 위해 팀원과의 소통으로 한층 더 단단하게 관리할 수 있게 되었어요.
Reference
링크드인으로 이야기를 주고받고 싶으시다면 언제든지 편하게 연락주세요. 🙇♂️